LARA - semantically annotated experimentation from ground up &
robotic enzyme screening for Machine Learning applications.
mark doerr & uwe bornscheuer & KIWI / SiLA / AnIML / NFDI4Cat teams institute for biochemistry, university
greifswald
greifswald/göteborg, 2024-03-27
ML biocatalysis - e.g. transamination reaction
- highly selective enzymes replace conventional chemistry
Structure- and Data-Driven Protein Engineering of Transaminases for Improving Activity and Stereoselectivity
Yu-Fei Ao et. al, Angewandte Chemie 2023. https://doi.org/10.1002/anie.202301660
3FCR transaminase substrate screening
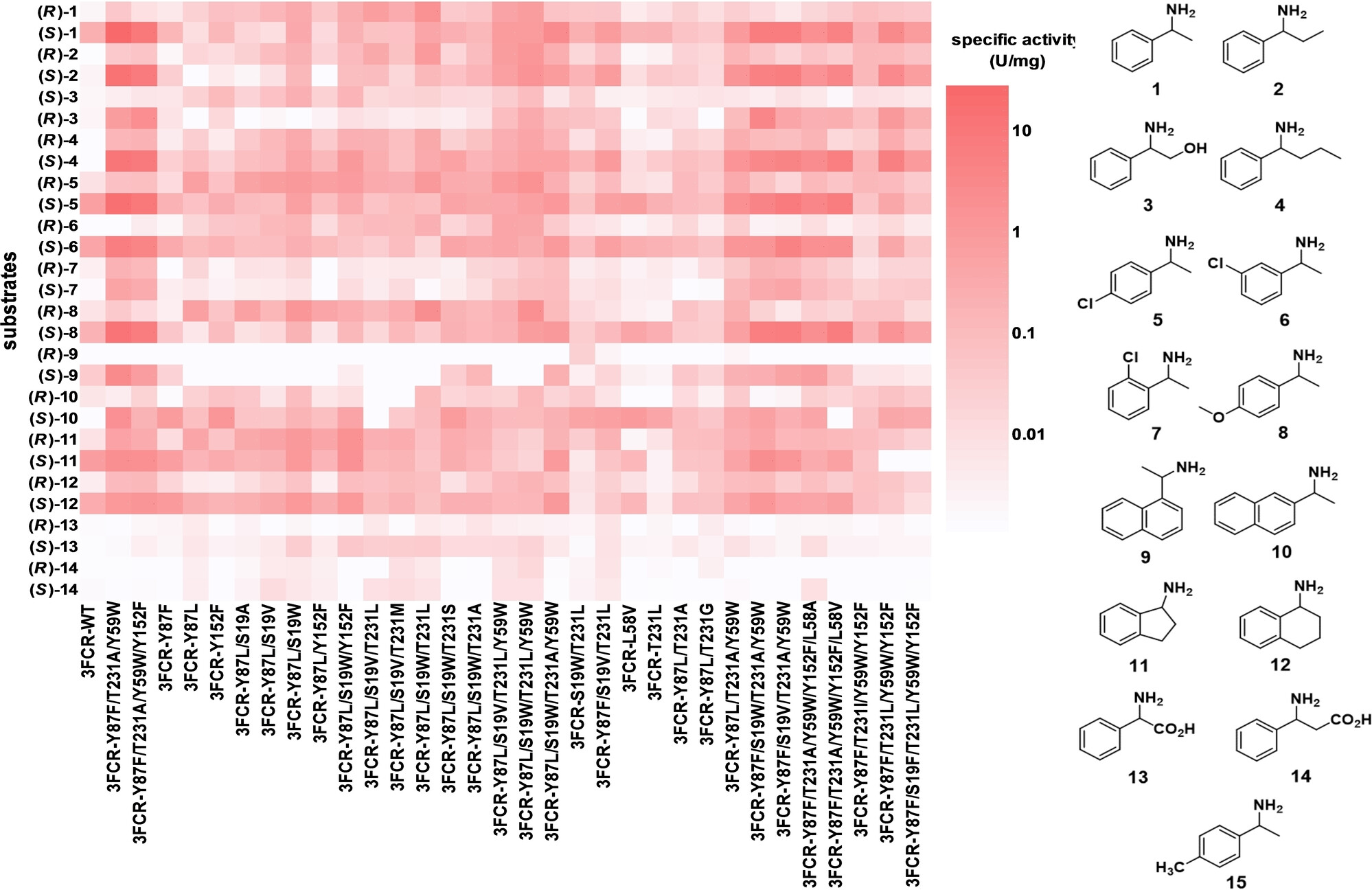
Structure- and Data-Driven Protein Engineering of Transaminases for Improving Activity and Stereoselectivity
Yu-Fei Ao et. al, Angewandte Chemie 2023. https://doi.org/10.1002/anie.202301660
"classical" ML approaches
Structure- and Data-Driven Protein Engineering of Transaminases for Improving Activity and Stereoselectivity
Yu-Fei Ao et. al, Angewandte Chemie 2023. https://doi.org/10.1002/anie.202301660
the greifswald protein screening platform LARA

requirements for semantics enabled machine learning




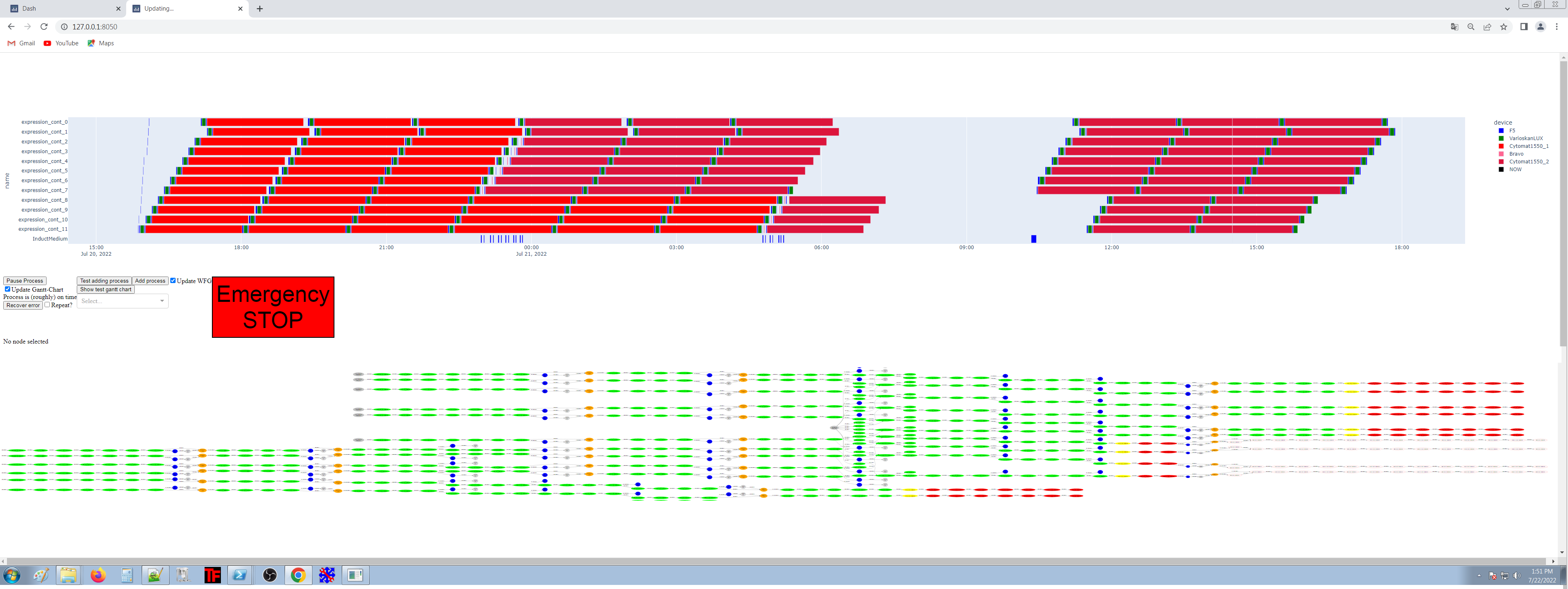
building homgeneous infrastructure from ground up



SiLA servers/devices of LARA

pythonLab
https://gitlab.com/opensourcelab/pythonLab universal, python based, automation language
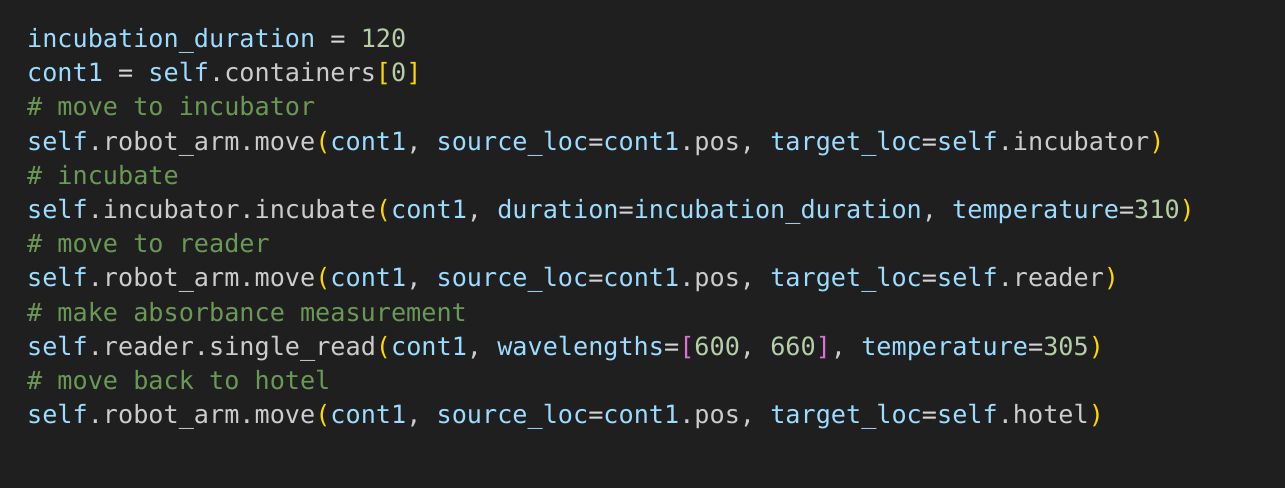
 pythonLabOrchestrator & Scheduler
pythonLabOrchestrator & Scheduler
https://gitlab.com/opensourcelab/pythonlabscheduler

pythonLabScheduler in the wild (stefan maak)
https://gitlab.com/opensourcelab/pythonlabscheduler
LabDataReader
https://gitlab.com/opensourcelab/LabDataReader
- generic data reader framework for propriatory (text based) data formats
- new data formats can be added as plugins
- rich meta data support
- automatic semantic annotation of the data
- fully written in python
- output formats: pandas data frame, JSON-LD, csv, (AnIML/JSON-LD - under development)
holistic approach of the LARA suite

- planning of experiments
- storing all required data for the planning, like literature, substances, material, devices, experimentalists ...
- generating the processes
- execution of the processes, communication with the lab devices
- collection of the data (very structured, well prepared to learn from it)
- evaluation and visualisation of the data (also DoE and machine learning)
- reporting / publishing / exchange between labs
overview of final architecture
fully open sourced and python based


ontology - development - for semantic search / ML

 EMMO - European Multiperspective Material Ontology
EMMO - European Multiperspective Material Ontology
- top- & mid level ontology
- sould theoretical foundation
- rooted in historical philosopy (mereology), topology, physics and quantum physics
- all ITEMS are, e.g., SpaceTime Objects
- multiperspective and multidisciplinary
- modelling and experiments
- small -> fast reasoning
- python representation (EMMOntoPy)
EMMOntoPy
(github.com/emmo-repo/EMMOntoPy)
- all OWL classes and Properties are modeled as Python Objects
- generation of an ontology and reaoning can be done completely in python
- modular / object oriented modelling possible
- easy interaction / integration in own python applications
- SPARQL endpoint
- fast SQLITE triple store
- code managed in git repository
- tools for validation, documentation and visualisation
ontology development pipeline

ontologies @ OpenSourceLab
exmple: OSO measurement
NFDI4Cat

 National Research Data Infrastructure - for Catalysis
National Research Data Infrastructure - for Catalysis

acknowledgements
project partners
- Stefan Born (TU Berlin)
- Peter Neubauer's group (TU Berlin)
- Johannes Kabisch's group and associates (Uni Trondheim)
- Egon Heuson (Uni Lille)
-
 Uwe Bornscheuer
and our group (Univ. Greifswald)
Uwe Bornscheuer
and our group (Univ. Greifswald)
KIWI-UG / NFDI4Cat
SiLA team
AnIML team
This work was supported by the German Federal Ministry of Education and Research through the Program “International Future Labs for Artificial Intelligence” (Grant number 01DD20002A)
We are grateful to the Deutsche Forschungsgemeinschaft (DFG, INST 292/ 118-1 FUGG) and the federal state Mecklenburg-Vorpommern for financing the robotic platform.