The RDM System LARA:
semantics through automation from bottom up
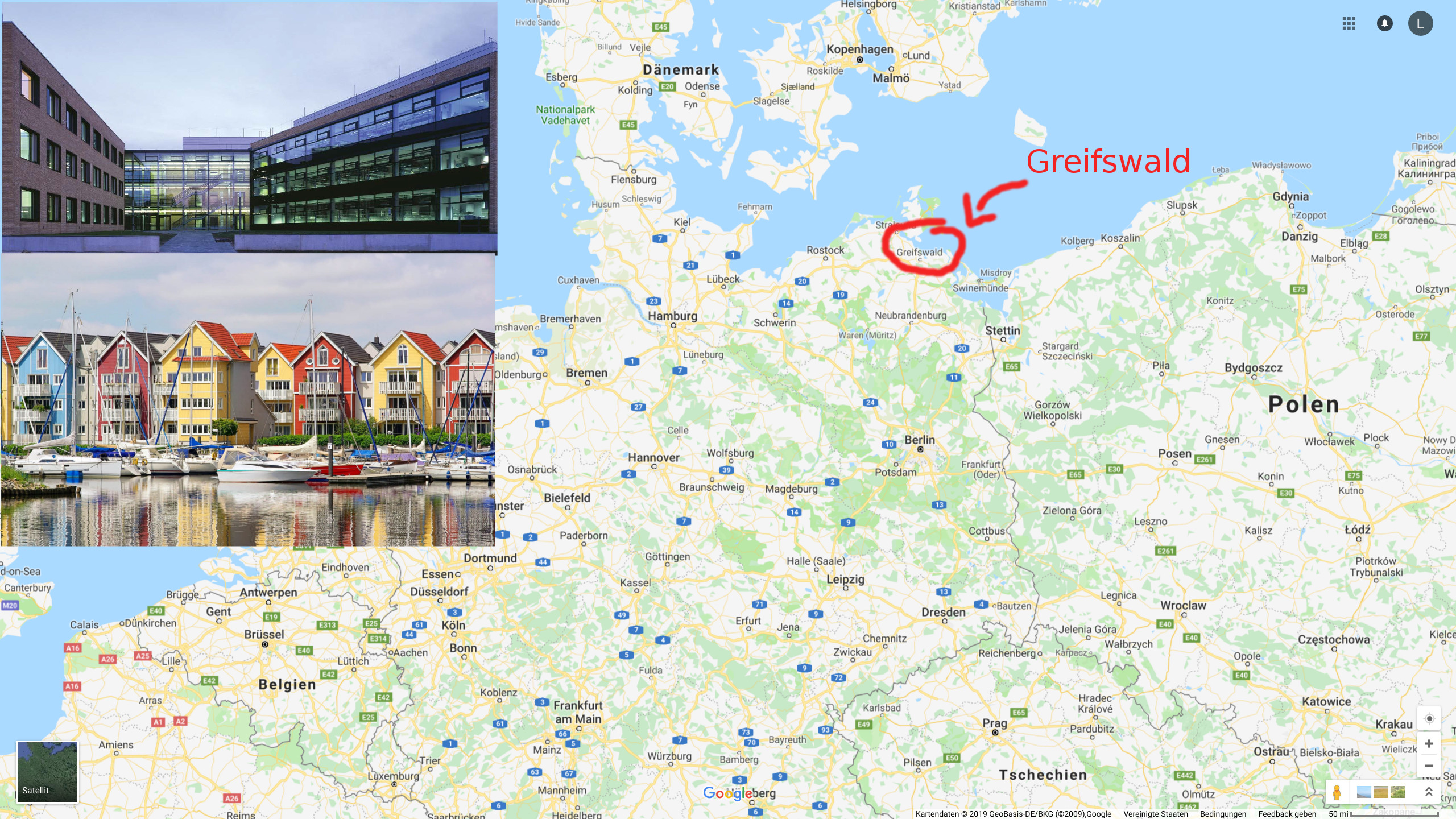
mark doerr, stefan maak & uwe t. bornscheuer institute for biochemistry, university
greifswald
Karlsruhe, 2023-09-14
Any element with the class="notes" will not be displayed. This can
be used for speaker notes. In fact, the impressConsole plugin will
show it in the speaker console!
Press ctrl-C to activate the console
* lara intro
the big vision

let's build ....

we made a plan ....
planning & control
*
 the project and experiment planning module
the project and experiment planning module
*
the (zotero) literature module
*
process execution: pythonLab, labOrchestrator pythonLabScheduler
*
process description language : pythonLab
universal, python based, automation language gitlab.com/opensourcelab/pythonLab
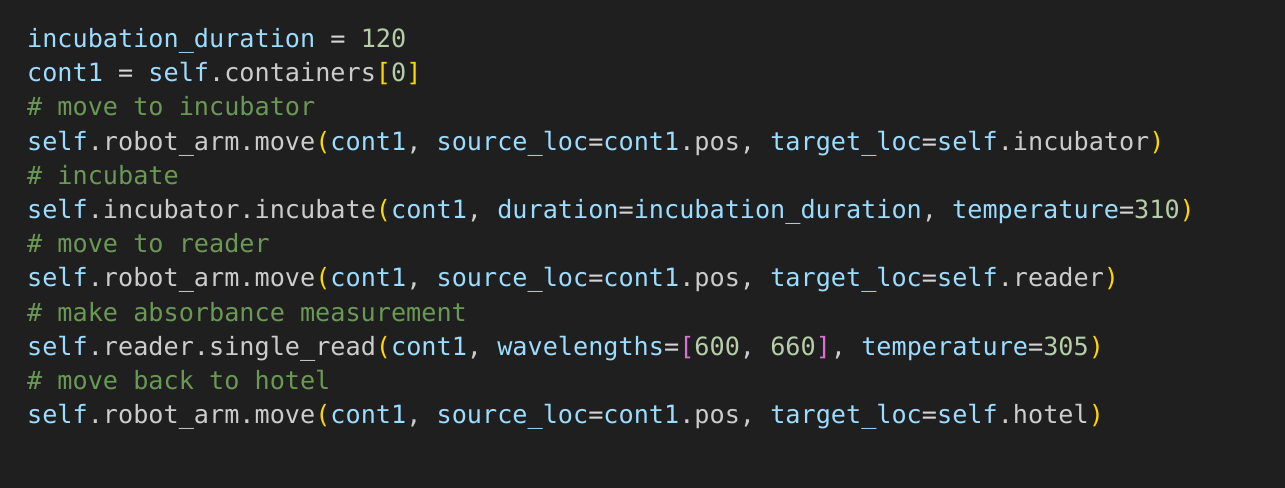
*

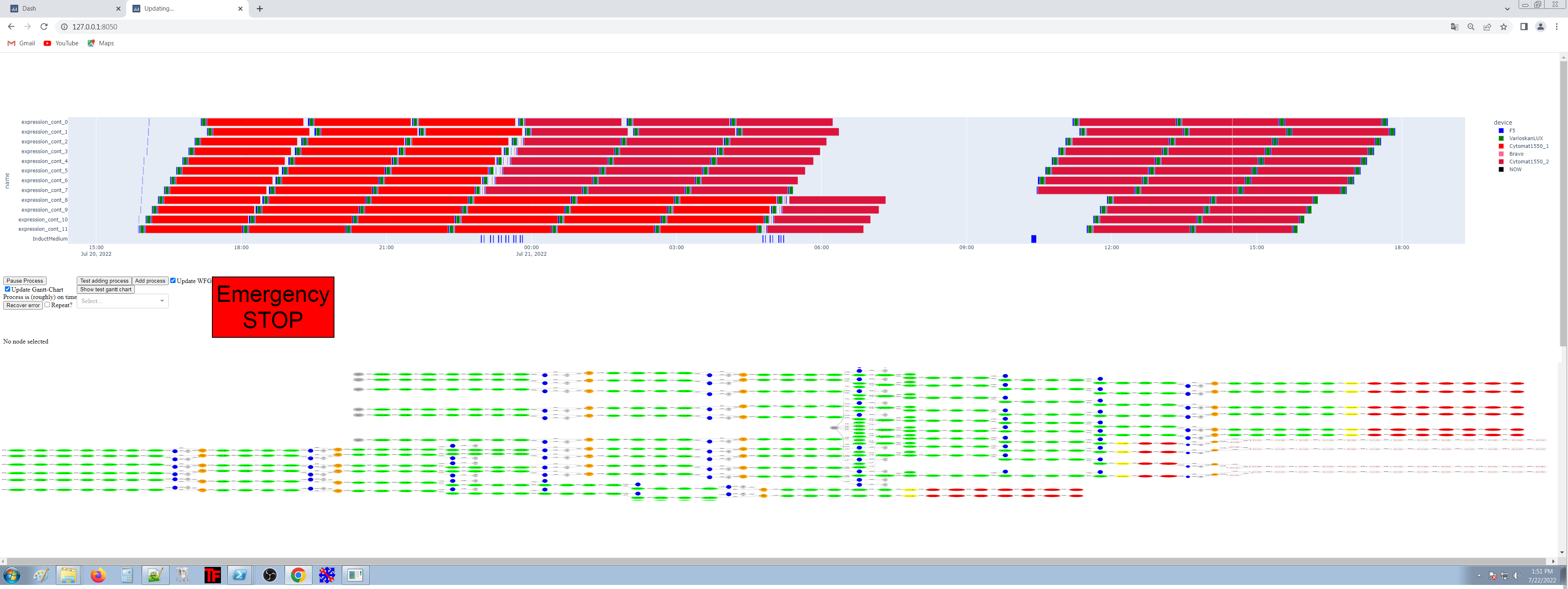
(meta-) data: data-transfer, storage, ontologies
*
what is  ?
?

sila-standard.org
- laboratory automation communication standard
- standardised data transfer
- standardised data storage (AnIML)
* feature
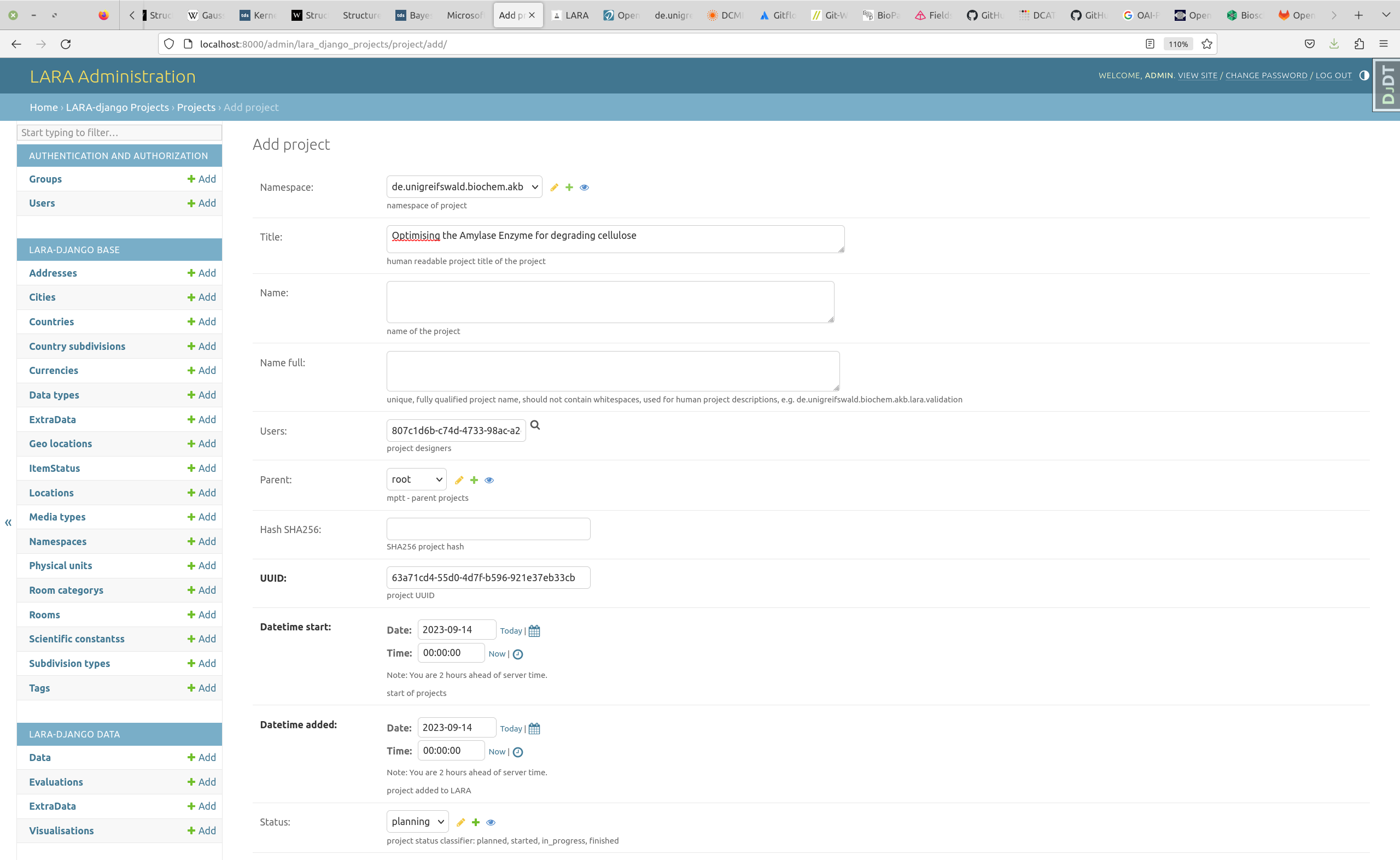
which data shall be stored ?

the data module
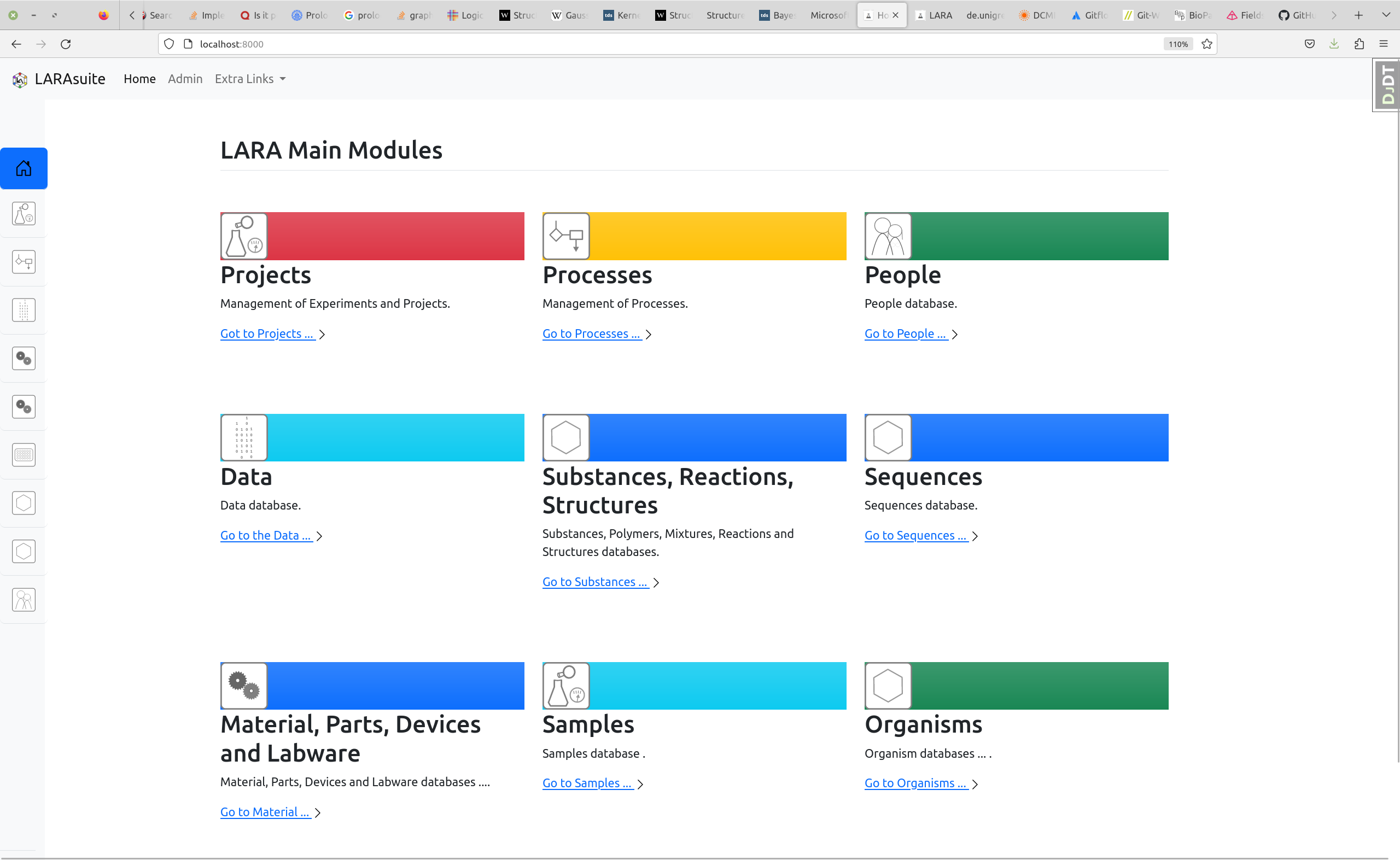
*
LabDataReader
https://gitlab.com/opensourcelab/LabDataReader
- generic data reader framework for propriatory (text based) data formats
- new data formats can be added as plugins
- rich meta data support
- automatic semantic annotation of the data
- fully written in python
- output formats: pandas data frame, JSON-LD, csv, (SciDat/AnIML - under development)
*

ontology - development - for semantic search / ML

*
 EMMO - European Multiperspective Material Ontology
EMMO - European Multiperspective Material Ontology
- top- & mid level ontology
- sound theoretical foundation
- rooted in historical philosopy (mereology), topology, physics and quantum physics
- all ITEMS are, e.g., SpaceTime Objects
- multiperspective and multidisciplinary
- modelling and experiments
- small -> fast reasoning
- python representation (EMMOntoPy)
*
EMMOntoPy
(github.com/emmo-repo/EMMOntoPy)
- all OWL classes and Properties are modeled as Python Objects
- generation of an ontology and reaoning can be done completely in python
- modular / object oriented modelling possible
- easy interaction / integration in own python applications
- SPARQL endpoint
- fast SQLITE triple store
- code managed in git repository
- tools for validation, documentation and visualisation
*
ontology development pipeline

*
ontologies @ OpenSourceLab
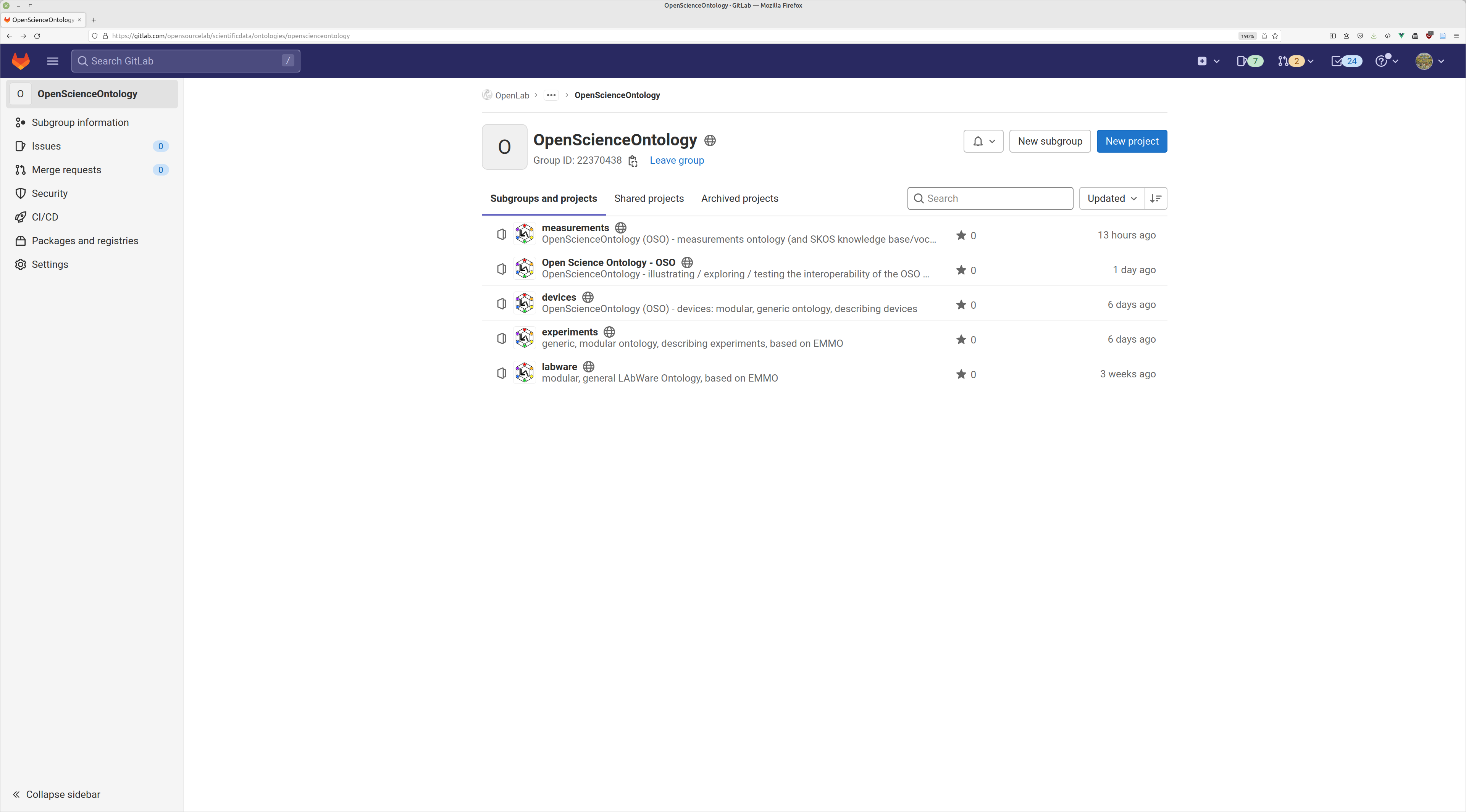
*
exmple: OSO measurement
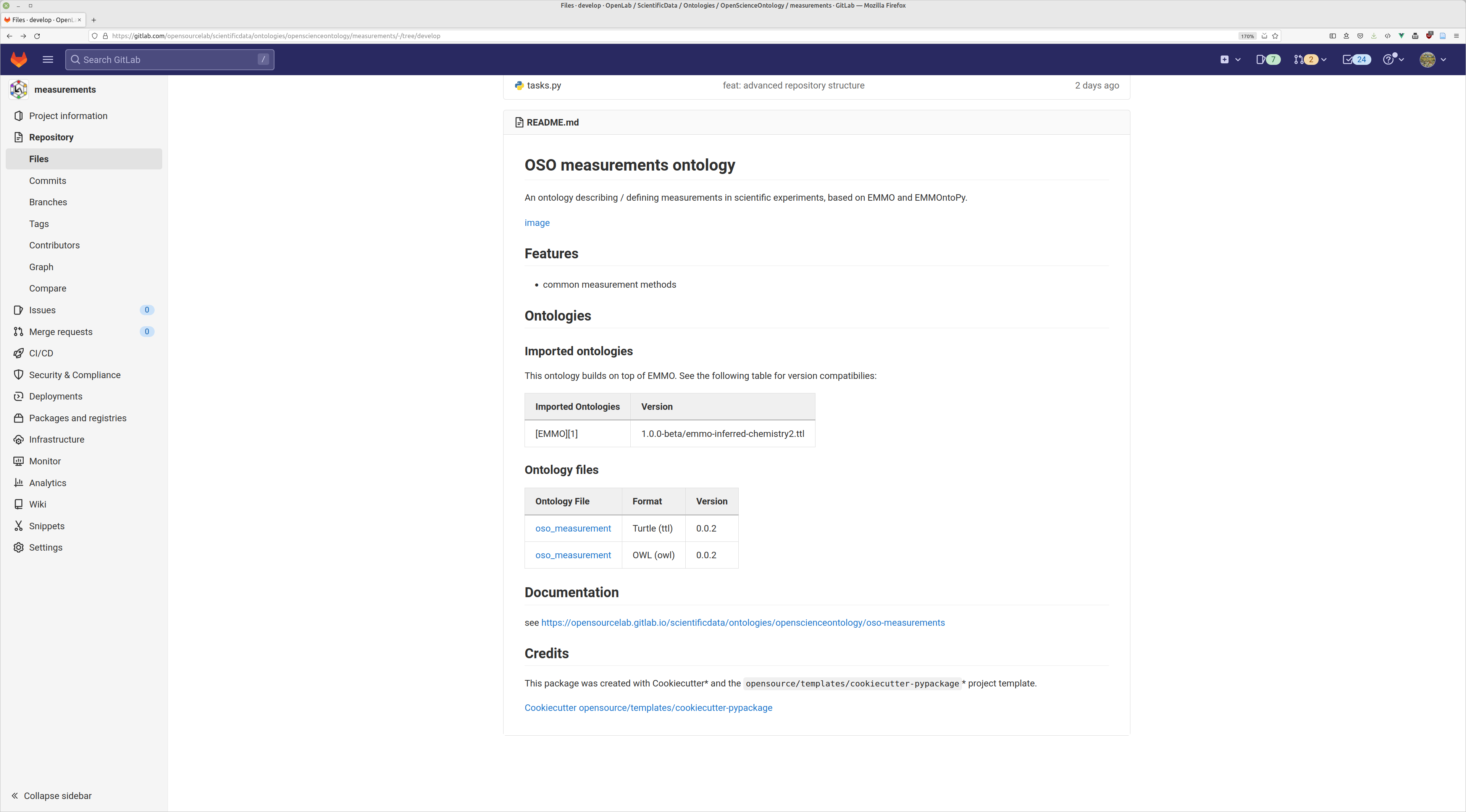
*
NFDI4Cat

 National Research Data Infrastructure - for Catalysis
National Research Data Infrastructure - for Catalysis
- TA1 ontology workgroup
- vocabulary / thesaurus for (bio-) catalysis
- vocabulary building pipeline
see talk of Alexander Behr et al., (Wed, 11:00h, Enabling RDM I)
working with (meta-) data: SPARQL, jupyter
*
build-in SPARQL interface
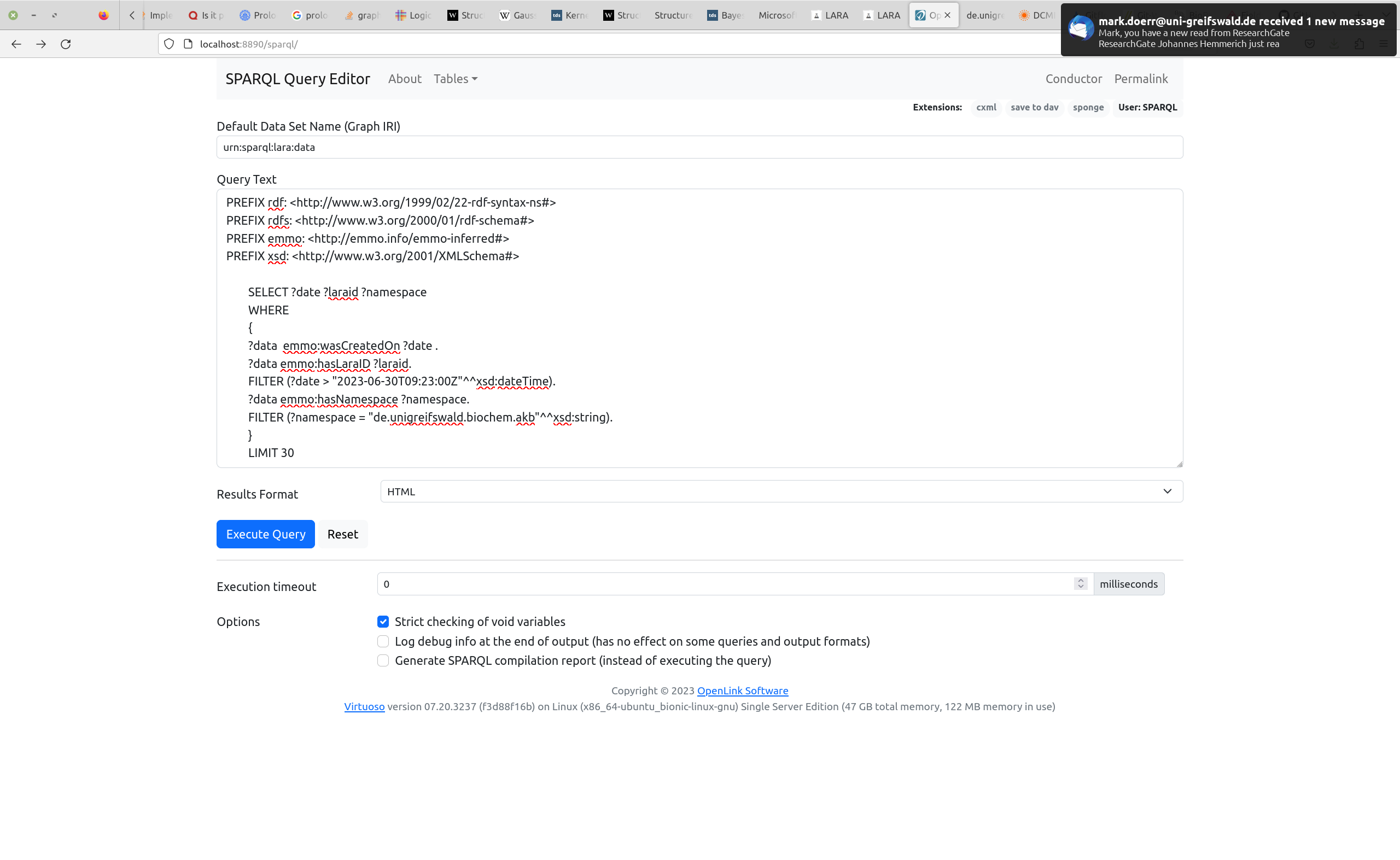
*
 working with jupyter
working with jupyter
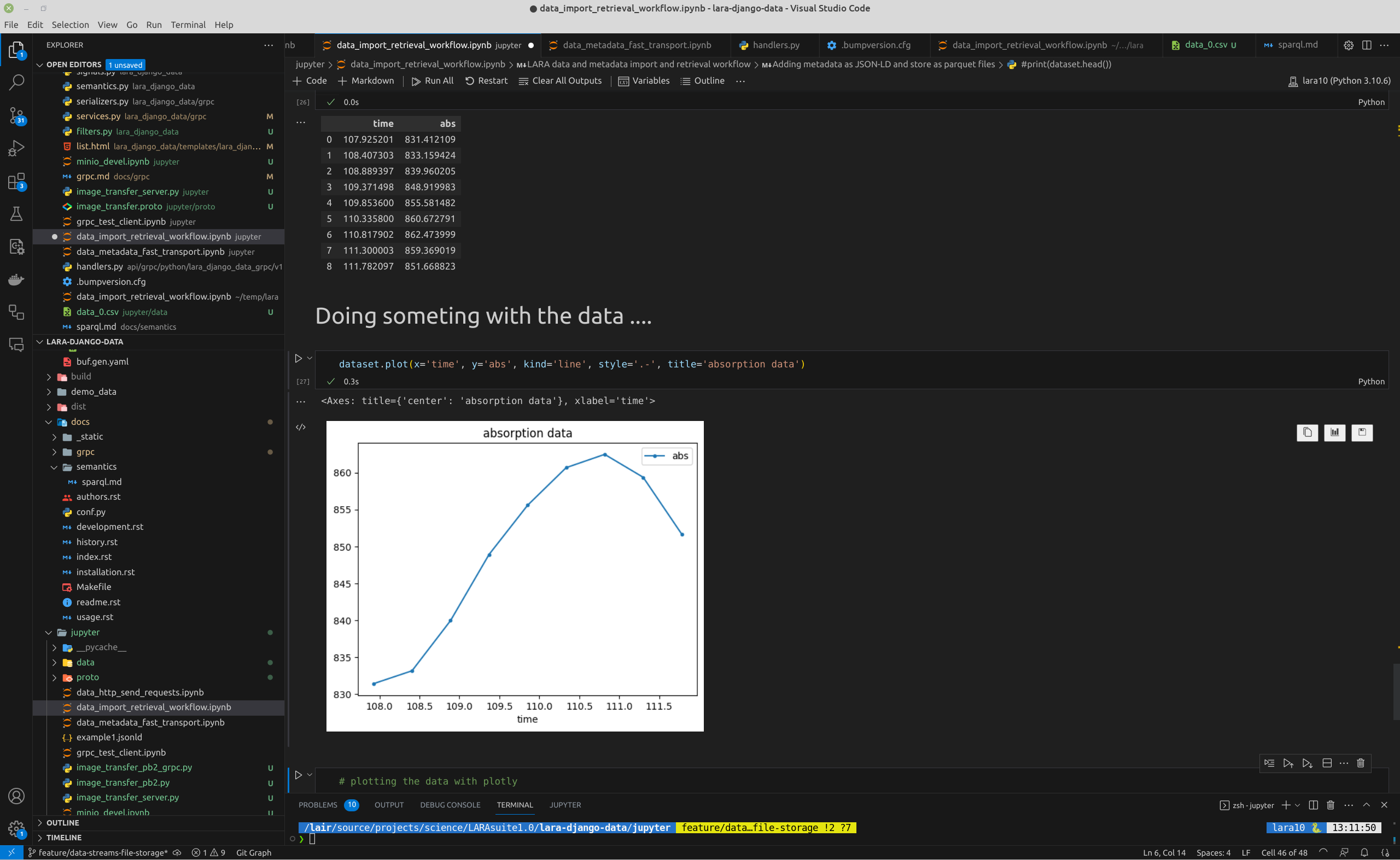
*
architecture: LARA
*

* lara intro
sharing data: collaborations, repositories, publications
*

* lara intro
implementation: all open source, python, gitlab
*
building homgeneous infrastructure from ground up

*


SiLA servers/devices of LARA

*

acknowledgements
project partners
- Stefan Born (TU Berlin)
- Peter Neubauer's group (TU Berlin)
- Johannes Kabisch's group and associates (Uni Trondheim)
- Egon Heuson (Uni Lille)
-
 Uwe Bornscheuer
and our group (Univ. Greifswald)
Uwe Bornscheuer
and our group (Univ. Greifswald)
KIWI-UG / NFDI4Cat
SiLA team
AnIML team
This work was supported by the German Federal Ministry of Education and Research through the Program “International Future Labs for Artificial Intelligence” (Grant number 01DD20002A)
We are grateful to the Deutsche Forschungsgemeinschaft (DFG, INST 292/ 118-1 FUGG) and the federal state Mecklenburg-Vorpommern for financing the robotic platform.