In-Depth High-Throughput Screening of Protein Engineering Libraries by Split-GFP Direct Crude Cell Extract Data Normalization
A new publication using the splitGFP system for high-throughput data normalisation and in-situ protein determination has recently been published in
Chemistry & Biology
http://www.sciencedirect.com/science/article/pii/S1074552115003385
Concernig the evaluation software suite, please stay tuned, a publication on github is coming soon. In urgent cases, please contact mark.doerr at uni-greifswald.de
Abstract
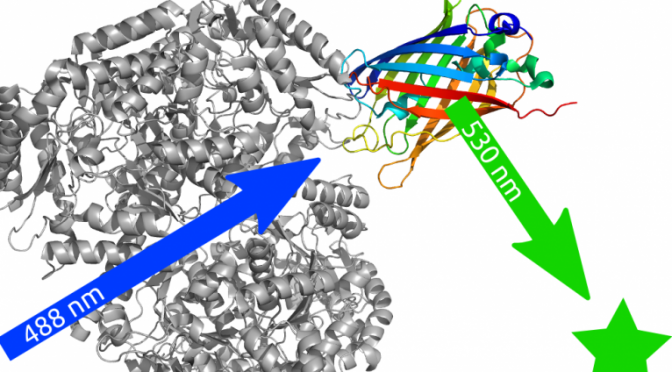
Here, we report a widely and generally applicable strategy to obtain reliable information in high-throughput protein screenings of enzyme mutant libraries. The method is based on the usage of the split-GFP technology for the normalization of the expression level of each individual protein variant combined with activity measurements, thus resolving the important problems associated with the different solubility of each mutant and allowing the detection of previously invisible variants. The small size of the employed protein tag (16 amino acids) required for the reconstitution of the GFP fluorescence reduces possible interferences such as enzyme activity variations or solubility disturbances to a minimum. Specific enzyme activity measurements without purification, in situ soluble protein expression monitoring, and data normalization are the powerful outputs of this methodology, thus enabling the accurate identification of improved protein variants during high-throughput screening by substantially reducing the occurrence of false negatives and false positives.
Sequences
(from Cabantous, S.; Waldo, G. S. In Vivo and in Vitro Protein Solubility Assays Using Split GFP. Nat Meth 2006, 3 (10), 845–854. https://doi.org/10.1038/nmeth932.)
Amino acid and sequence of the GFP 11 cassette:
SSLKRRKIPMGSSHHHHHHSSGLVPRGSHM*(frame shift +1)
*LIGSDGGSGGGSTSRDHMVLHEYVNAAGIT*GT*LEHHHHHH*DPAANKARKEAELAAATAEQ*LA*PLEA
DNA sequence of the GFP 11 cassette
0421007
TAGAGATACTGAGCACATCAGCAGGACGCACTGACCGAGTTCATTAAAGAGGAGAAAGATACCATGGGCAGCAGCCATCATCATCATCATCACAGCAGCGGCCTGGTGCCGCGCGGCAGCCATATGTAATTAATTAATTGGATCCGATGGAGGGTCTGGTGGCGGATCAACAAGTCGTGACCACATGGTCCTTCATGAGTACGTAAATGCTGCTGGGATTACATAAGGTACCTAACTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCTCTAGAGGCCTC
02129811
Amino acid sequence of the GFP 1-10 cassette
DRDLDPAKLIRLTIHMGGTSMSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATIGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKRHDFFKSAMPEGYVQERTISFKDDGKYKTRAVVKFEGDTLVNRIELKGTDFKEDGNILGHKLEYNFNSHNVYITADKQKNGIKANFTVRHNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQTVLSKDPNEK*GTLEHHHHHH*DPAANKARKEAELAAATAEQ*LA*PLEA
DNA sequence of the GFP 1-10 cassette
01079936
AGGATCGAGATCTCGATCCCGCGAAATTAATACGACTCACTATACATATGGGTGGCACTAGTATGAGCAAAGGAGAAGAACTTTTCACTGGAGTTGTCCCAATTCTTGTTGAATTAGATGGTGATGTTAATGGGCACAAATTTTCTGTCAGAGGAGAGGGTGAAGGTGATGCTACAATCGGAAAACTCACCCTTAAATTTATTTGCACTACTGGAAAACTACCTGTTCCATGGCCAACACTTGTCACTACTCTGACCTATGGTGTTCAATGCTTTTCCCGTTATCCGGATCACATGAAAAGGCATGACTTTTTCAAGAGTGCCATGCCCGAAGGTTATGTACAGGAACGCACTATATCTTTCAAAGATGACGGGAAATACAAGACGCGTGCTGTAGTCAAGTTTGAAGGTGATACCCTTGTTAATCGTATCGAGTTAAAGGGTACTGATTTTAAAGAAGATGGAAACATTCTCGGACACAAACTCGAGTACAACTTTAACTCACACAATGTATACATCACGGCAGACAAACAAAAGAATGGAATCAAAGCTAACTTCACAGTTCGCCACAACGTTGAAGATGGTTCCGTTCAACTAGCAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTCGACACAAACTGTCCTTTCGAAAGATCCCAACGAAAAGTAAGGTACCCTCGAGCACCACCACCACCACCACTGAGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCTCTAGAGGCCTC
02129811